title: " Odysseus架构拆解 | 本地AI工作台" date: 2026-06-22 category: 人工智能 tags:
- 大模型API中转站
- Odysseus
- Self-hosted AI Workspace
- Docker
- MCP
- 4SAPI description: "不从网红项目和安装体验切入,而是把 Odysseus 当成一个自托管 AI 工作台来拆:四个容器、数据目录、模型入口、搜索/记忆/MCP 链路,以及接入 4SAPI 后的多模型治理方式。"
最近 Odysseus 很火。
截至 2026-06-17 下午,我通过 GitHub API 看到这个仓库已经有 7.2 万以上 Star、9 千以上 Fork,仓库创建时间是 2026-05-31,默认分支是 dev,许可证是 AGPL-3.0。这个增长速度当然值得看一眼,但如果只盯着 Star,很容易把它看成一个热闹项目。
我更关心另一个问题:
Odysseus 到底是不是一个“本地版 ChatGPT”?
答案是:不是。
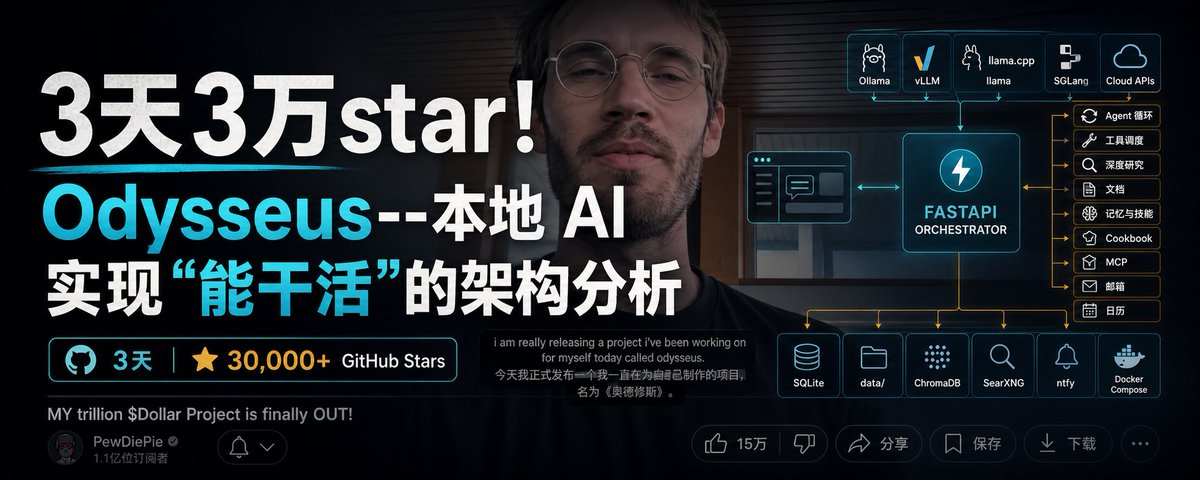
它更像一个自托管 AI 工作台。聊天只是入口之一,真正的重点在后面:文档、邮件、日历、Notes、Tasks、Deep Research、本地模型、外部 API、MCP 工具、记忆库和搜索服务,都被收进同一个 Web 工作区。
这篇不写“我安装了一遍”的体验流水账,而是从架构角度拆开看:
Odysseus 到底由哪些组件组成?
数据存在哪里?
模型请求怎么走?
为什么它适合接大模型API中转站?
它和 Dify、n8n、LibreChat、Claude Code 的边界在哪里?
看完这篇,你不一定要立刻部署,但至少能判断它是不是适合你的工作流。
1. 先别看功能列表,先看它想占哪一层
AI 工具可以粗略分成四层:
| 层级 | 代表工具 | 核心问题 |
|---|---|---|
| 模型层 | Claude、GPT、Gemini、DeepSeek、Qwen | 谁来生成答案 |
| API 网关层 | 4SAPI、OpenRouter、官方 API 网关 | 怎么接入、计费、路由和限流 |
| Agent/应用层 | Claude Code、Codex、Hermes、Dify | 怎么执行任务 |
| 工作台层 | Odysseus、部分自托管知识工作区 | 资料、任务、记忆和工具放在哪里 |
很多人第一次看到 Odysseus,会把它归到“聊天界面”这一类。
但它真正想做的是工作台层。
普通聊天界面的中心是一个输入框:
你输入问题
模型回答
对话结束
Odysseus 想做的中心是一个工作环境:
你上传资料
连接模型
调工具
做研究
写文档
整理邮件
留下记忆
安排后续任务
这两种产品的差异很大。
聊天工具解决的是“这一轮怎么答”;工作台解决的是“这件事怎么持续推进”。所以看 Odysseus 的时候,不要只问“它回答得好不好”,还要问:
它能不能保存上下文?
它能不能接不同模型?
它能不能把搜索、文档、任务串起来?
它出了问题能不能恢复?
它的权限边界有没有说清楚?
这些问题,比界面好不好看更重要。
2. Docker 启动后,其实是四个服务在协作
官方推荐 Docker 启动。默认 docker compose up -d --build 以后,不只是跑了一个 Web 应用,而是拉起了一组配套服务。
官方 compose 里核心组件大致是:
| 服务 | 默认访问 | 作用 |
|---|---|---|
odysseus |
127.0.0.1:7000 |
主应用、Web UI、Agent、模型配置、文档/任务/邮件等入口 |
chromadb |
127.0.0.1:8100 |
向量数据库,承载记忆和 RAG 类能力 |
searxng |
127.0.0.1:8080 |
元搜索服务,给 Deep Research 和网页搜索提供入口 |
ntfy |
127.0.0.1:8091 |
通知服务,用于提醒、任务通知等场景 |
这张表很关键。
因为它说明 Odysseus 不是一个“前端套壳”,而是一个把搜索、记忆、通知和 AI 应用绑在一起的本地栈。
可以把它想成这样:
浏览器
|
v
Odysseus Web / API
|
|-- 模型入口:本地模型 / 官方 API / 4SAPI 等中转站
|
|-- ChromaDB:记忆、向量检索、RAG
|
|-- SearXNG:网页搜索、研究任务
|
|-- ntfy:提醒、任务通知
|
|-- data/:账号、会话、文档、上传文件、设置
这也是它和很多轻量聊天 UI 的差异。
轻量聊天 UI 通常只解决:
我有一个 Key,怎么发请求?
Odysseus 要解决的是:
我有一堆资料、一堆模型、一堆任务,怎么放到同一个地方持续使用?
3. 默认只绑本机,是一个很好的安全信号
官方 Docker 配置里,主应用默认绑定到 127.0.0.1。这意味着它默认只在本机可访问。
这是一个正确的默认值。
因为 Odysseus 的权限比普通 Web 应用重得多。它可能接触:
本地文件
上传文档
邮件内容
日历内容
API Key
模型服务
MCP 工具
Shell / Python 执行能力
如果一个工具只会聊天,把端口暴露出去已经有风险;如果一个工具还可能读写文件、发邮件、执行工具,那它就应该被当作“管理员控制台”对待。
所以第一条原则是:
先在本机或可信内网跑通,不要裸露到公网。
需要手机或另一台电脑访问,可以走更稳妥的路径:
| 访问方式 | 建议 |
|---|---|
| 本机测试 | 保持 127.0.0.1 |
| 家庭内网 | 只开放给可信网段,保持登录认证 |
| 远程访问 | 优先 Tailscale / Zero Trust / VPN / 反向代理认证 |
| 公网直连 | 不建议直接暴露原始端口 |
这不是保守,而是因为它的能力边界决定了安全边界。
4. 数据目录比代码目录更重要
自托管工具最容易被忽略的一点是:真正值钱的不是应用代码,而是数据目录。
Odysseus 的代码你可以重新 clone,镜像可以重新 build,但 data/ 里可能有:
账号与会话
应用数据库
历史对话
文档
上传文件
记忆
模型设置
Provider 配置
个人资料
备份文件
官方文档也强调,用户数据主要在 data/ 下,并且这些内容默认应该被 Git 忽略。
如果你准备长期使用,先把这几个动作写进自己的运维清单:
1. 明确 APP_DATA_DIR 放在哪里。
2. 确认 .env、data、logs 不进入 Git。
3. 定期备份 data 目录。
4. 升级前先备份 data 和 .env。
5. 截图、演示、分享日志前先检查 Key 和私密数据。
这类工具一旦用顺手,里面沉淀的东西会越来越多。真正迁移时,最痛的不是重新部署,而是找不到当初那些资料、记忆和设置。
5. 模型入口分三类:本地、官方、中转站
Odysseus 的一个核心价值,是把模型从工作台里解耦出来。
你可以把模型入口分成三类:
| 入口 | 适合场景 | 优点 | 风险 |
|---|---|---|---|
| 本地模型 | 私密资料、离线实验、低频任务 | 数据更可控,边际调用成本低 | 硬件、驱动、模型质量、上下文受限 |
| 官方 API | 高质量推理、强模型能力、厂商特性 | 能力稳定,文档清晰 | 多厂商适配和账单分散 |
| 大模型API中转站 | 多模型统一入口、成本统计、快速切换 | 一个 base_url 管多模型,便于治理 |
需要选择可信服务和合规用途 |
这也是 4SAPI 这类中转站适合接入 Odysseus 的原因。
如果你直接在 Odysseus 里分别配置 OpenAI、Anthropic、DeepSeek、Gemini、OpenRouter,每个入口都要单独维护:
Key 在哪里?
模型名怎么写?
额度怎么控?
哪个任务用了多少 Token?
测试环境和生产环境怎么隔离?
而通过 OpenAI 兼容的大模型API中转站,可以把一部分复杂度收敛成:
base_url = https://4sapi.com/v1
api_key = 单独生成的 Odysseus 专用 Key
model = 按任务切换
注意,这里说的是合法合规的统一接入、账单管理和模型路由,不是用来绕过官方规则。
6. Odysseus 里的“模型”不是唯一成本源
很多人算 AI 成本,只盯着聊天的一问一答。
在 Odysseus 这种工作台里,成本来源会更分散:
| 功能 | 可能产生的成本 |
|---|---|
| Chat | 普通输入输出 Token |
| Compare | 同一个问题同时打给多个模型,成本按模型数放大 |
| Deep Research | 多轮搜索、阅读、总结,会连续调用模型 |
| Documents | 改写、总结、建议、导出前整理 |
| Memory / RAG | Embedding、召回、上下文拼接 |
| 摘要、分类、回复草稿 | |
| Tasks | 定时后台任务可能在你不盯着的时候调用模型 |
所以,接入 4SAPI 这类中转站时,不建议直接把主账号 Key 填进去。
更稳妥的做法是:
为 Odysseus 单独建 Key
限制每日/月度预算
先只开放少量模型
用低成本模型跑普通任务
把强模型留给复杂推理和终稿检查
定期看调用日志
Odysseus 的工作台能力越强,越需要成本治理。否则你以为自己只是聊了几句,实际上后台研究、对比、文档处理和定时任务都在消耗额度。
7. 工作台的关键不是“拼组件”,而是状态能否贯通
从组件看,Odysseus 并没有把每个能力都从零造一遍。
官方 acknowledgments 里写得很清楚:它借鉴和改造了开源项目,也通过 Docker 组合了 SearXNG、ChromaDB、ntfy 等服务。
这不丢人。
真实产品里,单点能力往往不是最难的。难的是让这些能力共用同一套上下文:
同一套账号
同一套权限
同一套数据目录
同一套模型配置
同一个任务状态
同一个可恢复的工作流
这就是工作台和工具箱的区别。
工具箱里有很多工具,但每个工具各管各的。工作台要解决的是:工具之间怎么交接,产物怎么留下,下次怎么接着做。
如果你只是想偶尔问几句,Odysseus 可能太重。
如果你每天都要做这些事,它就开始有意义:
查资料
写长文
整理文档
比较模型
处理邮件
保存项目记忆
让 Agent 做定时任务
在本地模型和 API 模型之间切换
8. 和 Dify、n8n、LibreChat、Claude Code 怎么区分
很多人会问:我已经有 Dify、n8n、LibreChat、Claude Code,还要 Odysseus 吗?
可以这样区分:
| 工具 | 更适合做什么 | 不擅长什么 |
|---|---|---|
| Dify | 搭 AI 应用、知识库问答、工作流产品化 | 个人工作台、邮件/日历/本地模型一体化 |
| n8n | 低代码自动化、跨 SaaS 编排 | 深度 AI 工作区和长期上下文 |
| LibreChat | 多模型聊天入口 | 任务、文档、邮件、日历和本地记忆整合 |
| Claude Code / Codex | 在具体代码仓库里读写代码、跑测试 | 个人资料库、邮件日历、长期工作台 |
| Odysseus | 自托管 AI 工作台、本地模型、多工具统一入口 | 企业级权限、成熟运维、稳定商业支持 |
所以它不是替代所有工具,而是占了一个中间位置:
比聊天 UI 重
比企业级 Agent 平台轻
比单一编程助手更泛化
比纯自动化工具更贴近个人工作环境
这也是为什么它适合折腾型创作者、开发者、小团队先试,而不适合一上来就承载公司核心生产流程。
9. 30 分钟架构 POC 清单
如果你想判断它值不值得继续投入,可以先做一个 30 分钟 POC,不要一上来把邮箱、日历、公司资料全接进去。
建议顺序如下:
第 1 步:只用 Docker 本机启动,确认 127.0.0.1:7000 可访问。
第 2 步:修改初始管理员密码。
第 3 步:只接一个模型入口,比如 4SAPI 的测试 Key。
第 4 步:上传一份低风险文档,测试摘要和问答。
第 5 步:跑一次 Compare,但只选 2 个模型。
第 6 步:跑一次 Deep Research,把轮数控制在较小范围。
第 7 步:看 data、logs、调用账单和任务记录。
第 8 步:关停再重启,确认数据是否保留。
这个 POC 的目标不是证明它有多强,而是回答四个问题:
| 问题 | 合格标准 |
|---|---|
| 部署能否稳定启动 | 重启后服务和数据都正常 |
| 模型链路是否可控 | Key、模型、费用都能追踪 |
| 数据是否可迁移 | 知道哪些目录必须备份 |
| 工作流是否真有价值 | 至少一个高频任务比原来顺手 |
如果这四个问题都答不上来,就先别继续加权限。
10. 小结:Odysseus 的主角不是模型,而是工作区
Odysseus 最值得看的地方,不是它短时间拿了多少 Star,也不是它塞了多少功能。
它真正有意思的地方是:
模型可以换,
工具可以换,
但工作区、数据、记忆和任务状态要留下。
这和大模型API中转站的思路很像。
4SAPI 这类中转站解决的是模型入口统一:不同模型通过统一 API 管起来。Odysseus 解决的是工作入口统一:不同资料、工具、任务和模型放在一个工作台里。
两者合在一起,才是比较完整的 AI 工作流:
4SAPI:统一模型接入、计费、切换和治理
Odysseus:统一资料、任务、记忆、研究和工具
一句话总结:
如果你只需要聊天,Odysseus 过重;如果你想搭自己的 AI 工作台,它值得做一次架构级 POC。
下一篇继续聊更关键的部分:Odysseus 的权限和安全审计。这个工作台能做的事越多,越不能把它当普通网页应用来部署。
参考资料
- Odysseus GitHub README:https://github.com/pewdiepie-archdaemon/odysseus
- Odysseus Setup Guide:https://github.com/pewdiepie-archdaemon/odysseus/blob/dev/docs/setup.md
- Odysseus Docker Compose:https://github.com/pewdiepie-archdaemon/odysseus/blob/dev/docker-compose.yml
- Odysseus Acknowledgments:https://github.com/pewdiepie-archdaemon/odysseus/blob/dev/ACKNOWLEDGMENTS.md
- 4SAPI 接入文档:https://4sapi.apifox.cn/